運動品牌Puma成功撤銷波蘭Sinda Poland鞋廠的歐洲共同體近似商標申請

歐盟普通法院(The General Court of the European Union)於今年(2016)2月25日針對運動品牌Puma SE(以下簡稱Puma)提出之商標異議做出了判決。本判決認為,Puma所擁有的美洲獅商標(詳參圖1、圖2),與其異議之波蘭鞋廠Sinda Poland Corporation sp.(以下簡稱Sinda Poland)(詳參圖3)申請中的商標確有相似。此判決翻轉了歐盟內部市場協調局(Office for Harmonization in the Internal Market,以下簡稱OHIM) 所作出兩商標不近似之決議。本判決中,歐盟普通法院判決認為,OHIM應撤銷Sinda Poland之商標申請,並命令Sinda Poland及OHIM支付Puma相關訴訟費用。
本爭議起始於2012年,波蘭鞋廠Sinda Poland申請一歐洲共同體商標(Community Trade Mark,簡稱CTM),該商標為一跳躍的貓科動物形狀(詳參圖3),並指定使用於鞋類及運動鞋類產品。OHIM於2012年9月公告Sinda Poland申請的商標,同年11月Puma向OHIM提起異議,表示Sinda Poland之商標(詳參圖3)與Puma之美洲獅商標(詳參圖1、圖2)過於近似,有令消費者混淆商品或服務來源之虞。然而,OHIM於2014年決議認為,Sinda Poland之商標係兩種跳躍動物之結合,形成獨特的動物圖案設計,與Puma之美洲獅商標不相似,應不具有混淆消費者的疑慮。
Puma向歐盟普通法院上訴,認為法院應撤銷Sinda Poland之商標申請,並要求Sinda Poland支付相關訴訟費用。歐盟普通法院於今年2月25日做出決議,認為Sinda Poland侵害了Puma之商標權,並指出OHIM未將系爭兩商標在視覺上及概念上之整體相似度列入考量。該法院認為「Puma與Sinda Poland之商標皆為黑色的動物剪影,兩商標之動物背部及腹部弧度雖有所不同,但兩商標無法否認地有相似之處。」
經過為期將近四年的爭訟,Puma成功撤銷了Sinda Poland近似商標之申請。對國際知名運動品牌如Puma而言,近似商標的存在將會造成品牌知名度及商譽的打擊。如何藉由排除近似商標之申請以鞏固品牌形象及消費者認同,對品牌企業而言是必須面對的重要課題。本案中,Sinda Poland之近似商標仍在申請階段時Puma即提起異議。Puma積極的維權行動,是品牌廠商能夠藉以參照的模範。

圖1 Puma跳躍美洲獅商標(註冊於尼斯分類第1-42類)(圖片來源:歐盟普通法院判決)
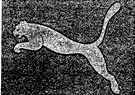
圖2 Puma跳躍美洲獅商標(註冊於尼斯分類第18、25、28類)(圖片來源:歐盟普通法院判決)

圖3 Sinda Poland欲申請之商標(註冊於尼斯分類第25類) (圖片來源:歐盟普通法院判決)
「本文同步刊登於TIPS網站(https://www.tips.org.tw)」

陶思妤
法律研究員 編譯整理
General Court ends Puma cat fight,Feb.25,2016 http://www.worldipreview.com/news/cjeu-ends-puma-cat-fight-9619?success_subscription=1(last visited :Mar.7,2016)
Puma SE v Office for Harmonisation in the Internal Market (Trade Marks and Designs) (OHIM),Mar.7,2016 http://curia.europa.eu/juris/document/document.jsf?text=&docid=174582&pageIndex=0&doclang=FR&mode=req&dir=&occ=first&part=1&cid=860012(last visited :Mar.7,2016)



加拿大交通部(Department of Transport Canada)於2019年1月發布「加拿大自駕系統安全評估(Safety Assessment for Automated Driving Systems in Canada)」文件,該文件將協助加拿大企業評估其發展高級(SAE第三級至第五級)自駕層級車輛之安全性,並可與美國相關政策進行整合。該文件指出,因相關技術尚在發展之中,不適合使用強制性規範進行管制,因此將利用引導性之政策措施來協助相關駕駛系統安全發展。加拿大交通部於文件中指出可用於評估目前自駕車輛研發成果之13種面向,並將其分類為三個領域: 自駕技術能力、設計與驗證:包含檢視車輛設計應屬何種自駕層級與使用目的、操作設計適用範圍、物件及事件偵測與反應、國際標準、測試與驗證等。 以使用者為核心之安全性:包含安全系統、人車界面與控制權的可取得性、駕駛/使用人能力與意識教育、撞擊或系統失靈時的運作等。 網路安全與資料管理:包含管理網路安全風險策略、售後車輛安全功能運作與更新、隱私與個資保障、車輛與政府分享之資訊等。 加拿大交通部鼓勵企業利用該文件提出安全評估報告並向公眾公開以增進消費者意識,另一方面,該安全評估報告內容也可協助加拿大政府發展相關安全政策與規範。
日本農林省研議農業AI契約指引日本為提高農產品品質及附加價值,近年積極推動智慧農業,鼓勵利用AI等新技術研發農業產品和相關服務,惟技術研發需要使用大量資料訓練AI模型,部分農業工作者擔心自身經驗及知識等資料在研發過程中外洩,為避免上述狀況發生,農林水產省於2019年7月9日召開「農業AI利用契約指引檢討會」(農業分野におけるAIの利用に関する契約ガイドライン検討会),研議「農業AI利用契約指引」,防止在進行AI相關應用研發時,農業工作者提供之資料不慎外洩或遭到不當利用,導致其權益受損。 「農業AI利用契約指引檢討會」於2019年12月19日舉辦第3次會議,公布農業AI利用契約指引草案,草案內容包括(1)總論︰說明本指引之制定目的、農業與AI的關係,以及本指引與其他類似指引之差異和適用範圍;(2)農業AI產品、服務契約基本事項︰說明利用AI研發之農業產品和服務相關之智慧財產權,契約要件(契約目的及契約當事人等)及農業AI模型研發流程等基本概念;(3)農業AI產品、服務契約注意事項︰說明AI產品和服務契約之特徵和注意事項,以及利用AI等新技術進行研發之當事人訂定契約時應注意的問題,如農業工作者所提供之資料的重要性、以及個人資料的處理方式等;(4)契約範本︰針對農業AI研發契約、農業AI產品和服務利用契約,以及向第三方提供農業資料之契約,說明契約內容重點及提供範本供作參考。
從匯流看我國電信與廣播電視產業之法律規範 歐盟加值稅(EU Value-Added Tax)2015新制簡介歐盟加值稅(EU Value-Added Tax) 2015新制簡介[1] 資策會科技法律研究所 法律研究員 吳建興 105年01月21日 壹、前言 在資通訊科技軟硬體發展下,現已邁向數位匯流的時代,傳統的電信、廣播電視業與網路業的界線已經模糊,而高速寬頻網路及行動載具的普及更促成新興數位內容服務業的發展,進而考驗著傳統經濟稅法的體制。由於數位經濟具有超越國界之特質,在數位經濟中跨境傳輸[2]加值稅之徵收造成很大挑戰[3],尤其更是對現代國家財政稅造成加深稅基侵蝕及企業利益移轉(BEPS)[4]之危險[5]。因此,歐盟經濟暨財政理事會於2008年通過[6]及公布[7]歐盟新制加值稅法案(VAT Package[8]),法案中關於電信、廣播及電子服務業服務提供地之規定於2015年1月1日正式生效,其目標便是針對數位服務業的加值稅課徵進行改革,以創造一個公平的數位服務市場,迎接數位經濟時代的來臨。 本文以下便就歐盟新制加值稅指令[9](Council Directive 2008/8/EC)區分為三個方向討論:首先界定加值稅新制影響標的和適用範圍以釐清影響範圍,其次說明改革的重點和規範效果,最後嘗試分析對服務提供者和納稅義務人的影響。 貳、新制適用對象 根據歐盟新制加值稅指令(Council Directive 2008/8/EC)第5條規定[10],本次新制規範對象限於數位服務業當中所稱之電信(Telecommunications)、廣播(Broadcasting)及電子(Electronic)服務業三大業別。換言之,「貨物的提供」與「電信、廣播及電子服務業之外其它服務業」則不在本次規範範圍中[11]。而所謂電信,廣播及電子服務,根據定義係指: 一、電信服務定義 電信服務是指經由有線、無線、光學或電子磁,為信號、文字、影像、聲音傳輸、發射、接收等服務。這些服務包含轉讓如此傳輸、發射、接收能力。此能力亦包含對全球資訊網路之連結[12]。具體實例如:固定與行動電話服務、視訊電話服務(Videophone)、經由廣播所傳輸訊息服務(paging services)、傳真、電報、網路連接服務及全球資訊網服務[13]。 二、廣播及電視服務定義 廣播及電視服務是指關於聲音,影音內容之服務,諸如基於一電視、廣播節目表,經由通訊網路(Communications Networks),在一媒體服務提供者之編輯責任下,所提供給大眾同時收聽或收看電視或無線廣播節目[14]。具體實例如:線上廣播服務、經由廣播及電視網路所傳輸廣播及電視節目[15]。 三、電子服務定義 依2006年11月之歐盟加值稅指令所指稱之電子服務是指透過網際網路(The Internet)或電子網路(An Electronic Network)所提供的服務,且依此方式所提供的服務性質是完全自動化並涉及人為最小的干涉,且無此資訊技術下便不能確保該服務之提供品質[16],具體實例如:VOD(Video on Demand),下載應用軟體(APPs)[17],線上下載音樂、線上遊戲、電子書、防毒軟體、線上拍賣等[18]。 貳、新制加值稅規範內容 歐盟新制加值稅規範主要內容是重新定義了所謂服務供應地(The place of supply),進而影響加值稅課徵地的認定。依新修正歐盟加值稅指令第58條規定,如電信服務、廣播及電視服務或電子服務業,對消費者提供服務,該服務之供應地為該消費者通常居所或永久居所。因此,歐盟新制加值稅最大改變,是將舊制中關於歐盟境內的電信,廣播,電子服務中B2C部分加值稅課徵地,由服務提供者所在地改為顧客所在地。至於B2B商業模式規範之課徵地,原即為顧客所在地,在此次新制則未調整。換言之,自2015年1月1日起,提供顧客如電信、廣播及電子服務業服務時,其課稅地為顧客所在地[19]。在新制下,係依照數位服務提供者之所在地位於歐盟境內或境外,認定納稅義務人及課稅地。可歸納如下[20]: 一、數位服務提供者在歐盟境內 數位服務提供者提供服務對象為歐盟會員國境內企業時,由該會員國徵收加值稅。加值稅納稅義務人即為接受該服務之企業。 數位服務提供者提供服務對象為歐盟會員國境內消費者時,由消費者所在國徵收加值稅,加值稅納稅義務人為服務提供者。 數位服務提供者提供服務對象為歐盟會員國境外企業或消費者時,數位服務提供者所在國不能徵收加值稅[21]。 二、數位服務提供者在歐盟境外 數位服務提供者提供服務對象為歐盟會員國境內企業時,由企業所在地會員國徵收加值稅,加值稅納稅義務人為接受該服務之企業。 數位服務提供者提供服務對象為歐盟會員國境內消費者時,由顧客所在國徵收加值稅,加值稅納稅義務人為服務提供者。 參、推動建立簡易報稅系統 承上,由於新制將課稅地由服務提供者所在地改為消費者所在地。此使得數位服務業者須向其消費者所在國家進行加值稅註冊登記,並繳納其應繳加值稅稅額。此對於數位內容服務業者而言,將造成龐大行政負擔。舉例而言,如果英國電子服務業者有一位保加利亞顧客在網路上每月支付10歐元作為會員費;根據新制,電子服務提供者需到保加利亞做加值稅登記及繳納,此時除非電子服務提供者學習保加利亞文,親自聯絡稅務當局做登記及繳納,否則繳納上產生相當困難。倘若英國電子服務業之消費者遍及全歐盟會員國,此時該英國電子服務業便須知道歐盟境內各國加值稅稅率及方式,管理成本將成重大負擔。歐盟預見到此不便,故為方便納稅人納稅,便推動建立了簡易型報稅系統(Mini One Stop Shop, MOSS)。歐盟新制加值稅指令[22]允許電信、廣播及電子服務提供業者透過此替代性納稅方式,只需在其企業建立據點之歐盟會員國內,使用MOSS報稅系統此單一線上窗口進行登記、申報及繳納加值稅,經由該MOSS系統即可達到移轉申報金額給相關消費者所在之會員國之功能,免除報稅上之不便。 肆、事件評析 數位時代的來臨,因為網路傳輸無國境,故以數位服務提供者所在地為課稅地已不能滿足數位時代的超越國界特性,以消費者所在地為提供地應是未來之數位時代稅制發展方向。 就歐盟新制加值稅改革旨在建立一公平競爭的數位內容服務市場而言,透過加值稅課徵地的調整,將能促使歐盟數位內容服務提供者已不能選擇將公司據點建立於低加值稅之會員國而提高其競爭力。此項改革不只符合歐盟內部之服務加值稅長期政策,且亦與加值稅改革之?國際潮流接軌。 就臺灣目前之現狀而觀察,在數位內容服務之加值稅徵收上仍有不公平之競爭現象存在於境外數位服務內容提供者與境內的提供者之間。按現行法令,雖加值稅課稅地是以消費者所在地為原則,亦即不論境外及境內之業者所適用之費率均以臺灣的加值稅稅率為主。然而按現行法令,台灣消費者在每一筆交易低於3000元以下得免此納稅義務[23],因數位內容交易存在低價格之特性,形成國家稅收為數不小之缺口。而且由於在境外數位服務的提供上,現行規定是由台灣消費者負擔申報義務[24],其結果造成境外數位服務的加值稅因為難以期待消費者自行申報而課徵困難,反而變相提高境外數位服務業者的價格競爭力,背離稅制之中立性原則。 在歐盟舊制加值稅改革前,因為歐盟數位服務業者選擇低稅率國去建立據點而造成不公平競爭之問題,已因為新制將課稅地改為消費者所在地而消除。臺灣現制是納稅義務是由消費者負擔,未在臺灣建立據點之境外業者亦無繳納加值稅之義務。對照台歐雙方制度,建議台灣未來之改革方向應將加值稅之納稅義務人改為跨境之數位服務提供者,且取消3000元以下得免繳納之義務,並參考前述MOSS系統提供境外業者便利申報繳納之精神,提供方便境外業者申報繳納之管道,以提高納稅意願,助益國內數位服務產業公平競爭環境之建立。 [1]簡介歐盟加值稅2015新制針對電子服務業,電信業及廣播電視業之規定 [2]特別是在企業提供對消費者之數位內容服務上,暨所謂的B2C(Business to Consumers)服務。 ‘The digital economy also creates challenges for value added tax (VAT) collection, particularly where goods, services and intangibles are acquired by private consumers from suppliers abroad’. id. at 7. [4] 英文原文為: Base Erosion and Profit Shifting [5] ‘While the digital economy and its business models do not generate unique BEPS issues, some of its key features exacerbate BEPS risks’. OECD, OECD/G20 Base Erosion and Profit Shifting : Project 2015 Final Reports: Executive Summaries, at 6. available at http://www.oecd.org/ctp/beps-reports-2015-executive-summaries.pdf (last visited, Oct. 15, 2015) [6] VAT package: Commission welcomes adoption by the ECOFIN Council of new rules on the place of supply of services and a new procedure for VAT refunds , European Council:Press Release Database , Feb. 12, 2008 , http://europa.eu/rapid/press-release_IP-08-208_en.htm?locale=en (last visited, Oct. 15, 2015) [7] Council Directive 2008/8/EC, 2008 O.J. (L44) 11. [8] The "VAT package" contains: a Directive on the place of supply of services; a mini one stop shop for telecom, broadcasting and e-commerce services; a Directive on procedures for VAT refunds to non-established businesses; a Regulation on the exchange of information between Member States which is necessary to underpin the new arrangements [9]歐盟指令2008/8/EC 修正所謂〈歐盟加值稅指令〉Directive 2006/112/EC: Council Directive 2008/8/EC of 12 February 2008 amending Directive 2006/112/EC as regards the place of supply of services, [10] Council Directive 2008/8/EC, art. 5, 2008 O. J. (L44) 11, 17. [11] EUROPEAN COMMISSION, Explanatory notes on the EU VAT changes to the place of supply of telecommunications, broadcasting and electronic services that enter into force in 2015 , (2014) , at, 11, http://ec.europa.eu/taxation_customs/taxation/vat/how_vat_works/telecom/index_en.htm#new_rules (last visited Oct. 20, 2015) [12] Council Directive 2006/112/EC, art. 24(2) ,2006 O. J. (L347) 1, 14. 條文原文如下:Telecommunications services shall mean services relating to the transmission, emission or reception of signals, words, images and sounds or information of any nature by wire, radio, optical or other electron magnetic systems, including the related transfer or assignment of the right to use capacity for such transmission, emission or reception, with the inclusion of the provision of access to global information networks。 [13] Guichet Unique, Impots.gouv.fr, http://www2.impots.gouv.fr/e_service_pro/tva_miniguichet/moss.html p. 7 (last visited Oct. 14, 2015) [14] Council Implementing Regulation (EU) No 1042/2013, art. 6b(1) ,2013 O. J. (L284) 1, 3.條文原文如下: Broadcasting services shall include services consisting of audio and audio-visual content, such as radio or television programmes which are provided to the general public via communications networks by and under the editorial responsibility of a media service provider, for simultaneous listening or viewing, on the basis of a programme schedule [15] Guichet Unique, Impots.gouv.fr http://www2.impots.gouv.fr/e_service_pro/tva_miniguichet/moss.html p.7 (last visited Oct. 14, 2015) [16]Council Implementing Regulation (EU) No 282/2011, art. 7(1) ,2011 O. J. (L77) 1, 5. 條文原文如下: Electronically supplied services’ as referred to in Directive 2006/112/EC shall include services which are delivered over the Internet or an electronic network and the nature of which renders their supply essentially automated and involving minimal human intervention, and impossible to ensure in the absence of information technology. [17]"Applications (software)" [18]Guichet Unique, Impots.gouv.fr, http://www2.impots.gouv.fr/e_service_pro/tva_miniguichet/moss.html p.7 (last visited Oct. 14, 2015) [19] Council Directive 2008/8/EC, art. 5, 2008 O. J. (L44) 11, 17. 新修正歐盟加值稅第58條文原文如下:The place of supply of the following service to a non-taxable person shall be the place where that person is established, has his permanent address or usually resides: (a) Telecommunications services; (b) radio and television broadcasting services; (c) electronically supplied services, in particular those referred to in Annex II. Where the supplier of a service and the customer communicate via electronic mail that shall not of itself mean that the service supplied is an electronically supplied service. [20] Telecommunications, broadcasting & electronic services, European Commission, http://ec.europa.eu/taxation_customs/taxation/vat/how_vat_works/telecom/index_en.htm (last visited, Oct. 15,2015) [21]但倘若此服務在歐盟內實質被使用及享受,此相關會員國則可徵收。舉例而言,一匈牙利仿毒軟體在其網站提供仿毒軟體下載給澳大利亞之顧客,此服務是不用課徵加值稅。然而若此服務是在一歐盟會員國使用或享用,此歐盟會員國可決定去徵收。Telecommunications, broadcasting & electronic services, European Commission, http://ec.europa.eu/taxation_customs/taxation/vat/how_vat_works/telecom/index_en.htm (last visited, Oct. 15,2015). 此為歐盟執委會官網上的例子:“Example A Hungarian company sells an anti-virus program to be downloaded through its website to businesses or private individuals in Australia. NO VAT But if the service is effectively used & enjoyed in an EU country, that country can decide to levy VAT (option for Member States)” [22] Council Directive 2008/8/EC, 2008 O.J. (L44) 11. [23]依民國100年5月6日財政部台財稅字第10004500190號規定, 外國事業團體於中華民國境內無固定營業場所而有銷售勞務者,該買受人同一筆勞務交易應給付報酬總額在新臺幣3千元以下者免繳納營業稅。 [24]營業稅法第二條第三款之規定,外國之事業、機關、團體、組織,在中華民國境內無固定營業場所者,營業稅的納稅義務人為「其所銷售勞務之買受人」。又按照財政部於民國九十四年所頒布「網路交易課徵營業稅及所得稅規範」,其中亦規定「在中華民國境內無固定營業場所之外國事業、機關、團體、組織,其利用網路銷售勞務予我國境內買受人者,應由勞務買受人依營業稅法第36條規定報繳營業稅」。