Amazon無法阻擋家居家飾用品零售商Williams-Sonoma對其提出之智財侵害訴訟,此訴訟案將持續進行…

美國高端家居家飾用品零售商Williams-Sonoma於美國加州北區聯邦地方法院指控電商巨頭Amazon企圖誤導消費者,使消費者認為Amazon是Williams-Sonoma授權的經銷商。
2018年12月14日Williams-Sonoma向法院提起了智財侵權等訴,主張Amazon犯有下列行為,並請求損害賠償及禁制令:
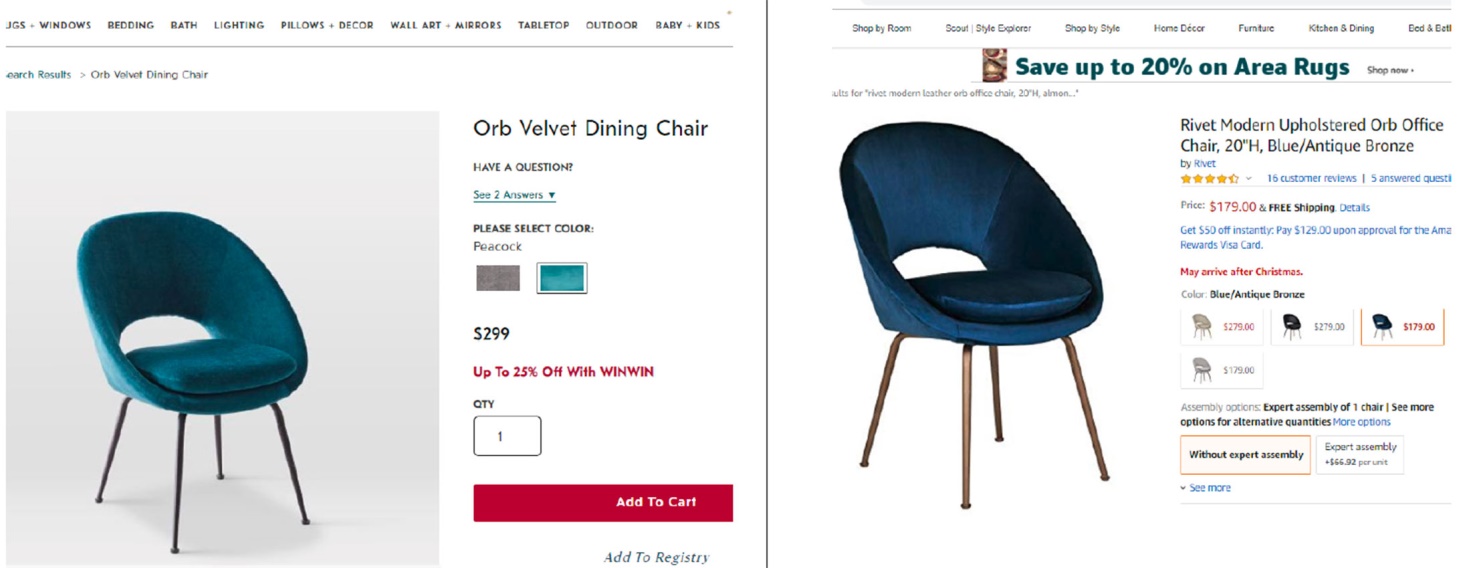
- 侵害了Williams-Sonoma旗下West Elm品牌的Orb椅子設計專利,專利號為D815,452。
- 在Amazon網站上及行銷廣告中使用Williams-Sonoma的商標而有商標侵害及仿冒之行為。
- 在Amazon網站上及行銷廣告中使用Williams-Sonoma的商標而有商標淡化之侵害行為。
- 不公平競爭行為。
Williams-Sonoma指出就商標部分,Amazon未經授權,在其網站設立一Williams-Sonoma銷售網頁,並在廣告及該網頁中使用未經授權的Williams-Sonoma商標,且未標示清楚網頁中的商品並非直接由Williams-Sonoma提供;甚至於Amazon的搜尋引擎廣告及電子郵件廣告中誤導消費者,使消費者認為可以在Amazon網站上買到Williams-Sonoma授權的商品。
Amazon於今(2019)年2月提出動議主張該案與商標相關之部分應予駁回,辯稱其僅是提供一個平台,使在其他地方購買的Williams-Sonoma產品可以轉售給消費者,適用第一次銷售原則。但該地院法官表示:「就整體而言Amazon不僅是轉售Williams-Sonoma的產品,而是塑造錯誤的印象讓人誤以為在Amazon網站的這些銷售是經過授權,使一個合理謹慎的消費者(reasonably prudent consumer)會產生誤認混淆。」,因此裁定駁回被告Amazon提出的動議,本案將會進入法院審判。
Williams-Sonoma提出的訴訟案其實也是Amazon發展自有品牌衍生的抄襲問題以及與其他大型品牌商緊張關係的展現。Amazon扮演著既是合作夥伴也是競爭者的角色,使得一些大型品牌商陷入困境,若不在Amazon網站銷售,產品很有可能會銷售不佳,但若在Amazon網站銷售,則Amazon會蒐集銷售產品的資料並且製造類似但較便宜的自有品牌產品銷售。Amazon此種飽受爭議的營運模式所牽扯的智財爭議仍有待後續追蹤 。
 圖片來源:COURT DOCUMENTS
圖片來源:COURT DOCUMENTS
「本文同步刊登於TIPS網站(https://www.tips.org.tw)」

廖晉瑩
法律研究員 編譯整理
Williams-Sonoma, Inc. v. Amazon.Com, Inc, No.18-cv-07548-EDL (May 2, 2019), available at https://images.law.com/contrib/content/uploads/documents/403/33688/Williams-Sonoma-v.-Amazon.Laporte-order-on-MTD-1.pdf
Powell Slaughter, Williams-Sonoma suit against Amazon continues, FURNITURETODAY, May 3, 2019, https://www.furnituretoday.com/e-commerce/williams-sonoma-suit-against-amazon-continues/ (last visited May 9, 2019).
Robert Burnson, Amazon Can't Duck Williams-Sonoma Suit Over Furniture Sales, BLOOMBERG, May 3, 2019, https://www.bloomberg.com/news/articles/2019-05-02/amazon-can-t-duck-williams-sonoma-suit-over-copycat-furniture (last visited May 9, 2019).
Robyn Smith, Everything we know so far about Williams-Sonoma v. Amazon, BUSINESS OF HOME, Dec. 21, 2018, https://businessofhome.com/articles/everything-we-know-so-far-about-williams-sonoma-v-amazon (last visited May 9, 2019).
Spencer Soper, Williams-Sonoma Accuses Amazon of Copying Its West Elm Furniture, BLOOMBERG, Dec. 19, 2018, https://www.bloomberg.com/news/articles/2018-12-18/williams-sonoma-accuses-amazon-of-copying-its-furniture (last visited May 9, 2019).



英國上議院人工智慧專責委員會(Select Committee on Artificial Intelligence)2018年4月18日公開「AI在英國:準備、意願與可能性?(AI in the UK: ready, willing and able?)」報告,針對AI可能產生的影響與議題提出政策建議。 委員會建議為避免AI的系統與應用上出現偏頗,應注重大量資訊蒐集之方式;無論是企業或學術界,皆應於人民隱私獲得保障之情況下方有合理近用數據資訊的權利。因此為建立保護框架與相關機制,其呼籲政府應主動檢視潛在英國中大型科技公司壟斷數據之可能性;為使AI的發展具有可理解性和避免產生偏見,政府應提供誘因發展審查AI領域中資訊應用之方法,並鼓勵增加AI人才訓練與招募的多元性。 再者,為促進AI應用之意識與了解,委員會建議產業應建立機制,知會消費者其應用AI做出敏感決策的時機。為因應AI對就業市場之衝擊,建議利用如國家再訓練方案發展再訓練之計畫,並於早期教育中即加入AI教育;並促進公部門AI之發展與布建,特別於健康照顧應用層面。另外,針對AI失靈可能性,應釐清目前法律領域是否足以因應其失靈所造成之損害,並應提供資金進行更進一步之研究,特別於網路安全風險之面向。 本報告並期待建立AI共通之倫理原則,為未來AI相關管制奠定初步基礎與框架。
美國專利訴訟趨勢與科技專案研發成果運用之法制研析 日本特許廳利用人工智慧審查專利與商標申請日本特許廳(Japan Patent Office,JPO)從去(2016)年12月開始,與NTT Data公司合作,使用人工智慧(Artificial Intelligence,簡稱AI)來系統化的回答有關專利問題,且依成果顯示,與原先運用人力回復的成果相當;JPO因此決定於今(2017)年夏天開始,將AI技術分階段應用於專利及商標的審查案,並期望能於下一會計年度(2018年4月至2019年3月),在審查業務中全面運用AI技術。 JPO指出,透過AI技術能有助於將專利及商標審查程序中繁冗的檢索程序簡化,以專利審查為例,可搜尋大量文件與檔案,進行專利先前技術檢索,以確保相關技術尚未獲得專利保護,同時也可以協助專利分類;此外,商標審查亦可利用AI之圖像辨識技術比對圖片及標誌,找出潛在的類似商標。 AI技術被證實能提升審查效率,並減輕審查人員檢索與比對部份的工作負擔,有助於抑制人工審查的長時間工作型態,根據2017年日本特許廳現況報告(特許庁ステータスレポート2017),於導入AI技術後,原本從申請到審查完成平均約2年左右之審查時間,期望可在2023年將審查期間降到14個月,讓日本成為智慧財產系統審查最快且品質最好的國家之一。 「本文同步刊登於TIPS網站(https://www.tips.org.tw)」
英國智慧財產局發布「標準必要專利2024年展望」,確立未來關鍵目標英國智慧財產局(Intellectual Property Office,下稱UKIPO)於2024年2月27日發布「標準必要專利2024年展望」(Standard Essential Patents: 2024 forward look),確立未來關鍵目標如下: (1)幫助專利實施者,尤其是中小企業可更好理解標準必要專利生態系,以及「公平、合理且無歧視」(Fair, Reasonable, and Non-Discriminatory, FRAND)授權原則; (2)針對定價和必要性,提高標準必要專利生態系的透明度; (3)加強使用仲裁和調解制度,提高爭議解決效率。 為達上述目標,英國計畫導入以下措施: 1.設立「標準必要專利資源中心」 UKIPO預計在2024年5月前設立一線上資源中心,以提供工具、指南和其他素材等方式,協助標準必要專利生態系中之專利實施者。 2.加強與國際及標準制定組織的交流 有鑑於SEP是全球性議題,UKIPO將就標準必要專利全球生態系挑戰,加快與其他國家有關當局的討論;UKIPO並將就智慧財產權政策及中小企業參與標準化等事宜,加強與標準制定組織之間的合作。 在推動上述措施後,UKIPO預計於2024年至2025年間展開一場「與技術相關」的公眾意見徵集(a public technical consultation)。UKIPO表示,任何需要進行SEP立、修法的方法都將是公眾意見徵集的一部分,惟不會包括「當標準必要專利被侵害時,是否要限制核發禁制令(injunction)」一事。