新德國包裝法簡介

為有效降低包裝廢棄物對環境造成的汙染及不利影響,使製造商履行其B2C(business to customer)產品責任,德國以新的包裝法(Packaging Act, VerpackG)取代現行的規範(Packaging Ordinance,VerpackV),並已於2019年1月1日生效。
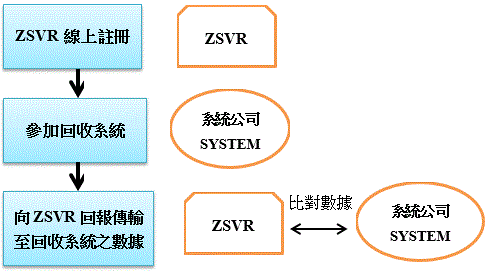
新包裝法VerpackG不同於VerpackV之處,在於除要求業者須加入原有的回收系統外,另授權Zentrale Stelle(Stiftung Zentrale Stelle Verpackungsregister,ZSVR)基金會作為新包裝法強制登記制度的執行單位,規範欲在德國銷售產品包裝之所有實體或網路製造商及零售商,有義務於ZSVR的數據資料庫”LUCID”註冊,才能在德國地區進行銷售,並且為全面提升透明度,乃規範於LUCID註冊之商家資訊皆屬可供大眾公開查詢。
依VerpackG規定,於2019年1月1日起未為註冊的商家,其包裝商品不能在德國上市,否則恐將臨100,000歐元之罰款;另未加入回收系統之商家,恐面臨200,000歐元之罰款。而除須註冊與回收系統的加入外,製造商及零售商尚須將以下之包裝相關資訊提供給ZSVR做比對:
(一)註冊號碼(商家於資料庫註冊時,由ZSVR所提供之註冊號碼)
(二)包裝材料及容積
(三)製造商履行生產者延伸責任(Extended Producer Responsibility)簽訂的包裝方案名稱
(四)與回收公司或回收系統間簽訂之契約期限
資料來源:自行繪製
圖 德國包裝法實施步驟

蔡宛君
法律研究員 編譯整理
How-To Guide to the Packaging Act for Manufacturers, Stiftung Zentrale Stelle Verpackungsregister(2018), https://www.verpackungsregister.org/fileadmin/user_upload/How-to-Guide_en_13072018_final.pdf (last visited Jun. 1, 2019)
The ten most important questions regarding the implementation of the Packaging Act ,Stiftung Zentrale Stelle Verpackungsregister(2018), https://www.verpackungsregister.org/fileadmin/user_upload/10-W-Fragen_en_13072018_final.pdf (last visited Jun. 1, 2019)
The new German Packaging Act is here – and it’s particularly important for online retailers,Der Grüne Punkt, https://www.gruener-punkt.de/en/services/packaging/german-packaging-act.html (last visited Jun. 4, 2019)



無人機(Drone)也就是無人飛機或無人飛行器(Unmanned Aerial Vehicles, UAV),具備自動飛行系統的簡易模型飛機,自動飛行系統內可能包含一電腦作業系統、一套衛星導航裝置、羅盤功能、氣壓高度計、偵測器及設計飛行之軟體等等,簡稱無人機。茲因電子與無線傳輸科技進步,無人機在國際間掀起流行,近來無人機之使用引發安全疑慮,促進各國重視無人機的使用與法制管理。目前國際間陸續針對無人機立法管理的有美國、日本及歐盟等,我國行政院亦於2015年9月24日通過「民用航空法」部分條文修正草案因應無人機遙控管理規範。觀諸國際立法及修法趨勢,無人航空器之管理,包括無人機的體積、重量、使用用途、使用區域限制、使用時間限制、飛行速度或方法、飛行高度限制等,且亦須重視安全、隱私、資料保護、損害責任與保險相關問題,以及無人機所有權明確判別之方式等,因此我國未來就無人機相關管理規範或可參考先進國家重要管理規定,擬定更適合我國之「無人航空器管理規則」,俾利發展新興科技無人機市場時,同時能兼顧確保個人、國家與領空安全之規劃。
基因改良作物命運大不同身為世上最大基因改良( GMO)棉花生產者的 中國大陸 ,已經批准將經過基因改良的混種棉花進行商業化,預料可以解決生活日用品上的短缺。相對於此, 歐盟 的農業部長們,卻對於是否批准編號1507的基因改良玉米,陷入一個進退維谷的困境。但是經過8年激烈的反對, 丹麥 卻允許基因改良玉米的進口。 而在 美國 有 85﹪的大豆,76﹪的棉花,45﹪的小麥是經過基因改良的。至於 澳洲 農業與資源經濟局則最近則對基因改良作物做出一份報告,認為各省禁止基因改良食品會減小經濟效益,使 澳洲 面對世界各地日益增多的基因改良作物發展,屈居弱勢。至終可能會在十年後造成1.5億到6億澳幣的損失。
法國CNIL提醒銀行App通話偵測防詐措施須兼顧合法性與用戶權利法國國家資訊自由委員會(Commission Nationale de l'Informatique et des Libertés, CNIL)於2025年7月15日指出近年來詐騙案件快速增加,詐欺行為人假冒銀行人員,以電話引導受害者自行完成轉帳或新增收款人等操作。為降低受騙風險,部分銀行在行動應用程式中設計機制,能偵測到使用者操作較高風險的交易時若同時處於通話狀態,便可即時跳出警示或暫停交易。此等做法雖有助於阻詐,惟因涉及個人資料存取,故須符合《歐盟一般資料保護規則》(General Data Protection Regulation, GDPR)之規範。 CNIL提醒銀行蒐集通話資訊須取得使用者明確同意,不能僅依賴行動裝置的「電話」權限,亦不得因使用者拒絕同意而限制應用程式之基本使用,僅在如新增收款人、大額轉帳、或轉帳至高風險國家等異常活動操作中才能要求同意,並須提供網站、電話或分行等替代辦理方式。又相關權限請求應在交易操作過程中提出,而非在應用程式安裝時統一要求,安裝前亦應向使用者充分說明。若使用者不同意,仍必須使其能正常查詢帳戶資訊。 此外,在資料處理上須遵循資料最小化原則,僅得蒐集是否進行通話及通話時長之資訊,不得恣意擴大資料蒐集範圍。與此同時,銀行應讓使用者在同意與撤回同意操作上一樣簡便,不得僅引導至手機裝置設定,而應使消費者能在應用程式中直接操作,並清楚告知撤回同意後功能受限範圍及可替代方案。 除利用應用程式進行通話偵測,CNIL建議銀行尚應搭配其他措施,例如在應用程式內定期推送防詐提醒、舉辦宣導活動,或在確認付款時詢問客戶是否正與自稱是「銀行顧問」之人通話。若銀行欲透過應用程式偵測通話狀態來防詐,則須在合法性、必要性、資料最小化以及使用者同意之間取得平衡。
電子投票機制及法律議題之研究