新加坡資料共享法制環境建構簡介

新加坡資料共享法制環境建構簡介
資訊工業策進會科技法律研究所
2019年12月31日
壹、事件摘要
如何有效運用資料創造最大效益為數位經濟(Digital Economy)重點,其中資料共享(data sharing)是有效方法之一。新加坡自2018年以來推動「資料共享安排」機制(Data Sharing Arrangements, 下稱DSAs)與「可信任資料共享框架」(Trusted Data Sharing Framework),建構資料共享環境,帶動國內組織[1]資料經濟發展與競爭力。
貳、重點說明
自從2014年新加坡政府推行「2025智慧國家(Smart Nation)」以來,即積極鋪設國家數位經濟建設,大數據資料分析等數位科技發展為其重點,預估2022年60%國內生產總值將與數位經濟有關[2] 。其中,希望透過資料共享促進組織、政府、個人三方間資料無障礙流通,降低蒐集、處理與利用成本,創造更多合作機會進行創新應用,因此從法制面、環境面與技術應用層面打造完善的資料共享生態系統(data sharing ecosystem)[3]。
然而依據《個人資料保護法》(Personal Data Protection Act 2012,下稱個資法)第14條以下規定,組織蒐集、處理與利用個人資料應取得當事人同意,除非符合第17條研究目的等例外情形。由於資料共享強調可將資料進行多節點快速傳遞近用,使資料利用價值最大化,因此若依據個資法規定每次共享皆須事前獲得當事人同意,將使近用成本增高並間接造成資料流通產生障礙。因此為因應國家政策與產業需求,新加坡個人資料保護委員會(Personal Data Protection Commission, 下稱個資委員會)依據個資法第62條所賦予的豁免權(exemption),個人或組織可在遵循個資委員會訂定的規則下,依照個案給予組織免除個資法部分規範[4] ,而DSAs機制即是一種[5]。
DSAs是由個資委員會於2018年設立的沙盒(sandbox)計畫,如組織所進行的共享模式是在特定群體並範圍具體明確,同時不會造成個人有負面影響等情事,可在不須經個人同意下進行資料共享[6]。並且,為進一步提升組織與消費者間信任,2019年6月個資委員會與資訊通信媒體發展局(Info-Communication Media Development Authority of Singapore,下稱資通發展局)共同推出「可信任資料共享框架」指南建議,由政府擔任監管角色,組織只要符合指南建議方向,如遵循法律、達到一定資料技術應用品質與實施資安與個資保護措施下,可以進行個人與商業資料之共享,DSAs機制是共享方法之一。以下簡述新加坡個資法規範、指南建議與DSAs機制運作方式。
圖1:資料共享環境建構
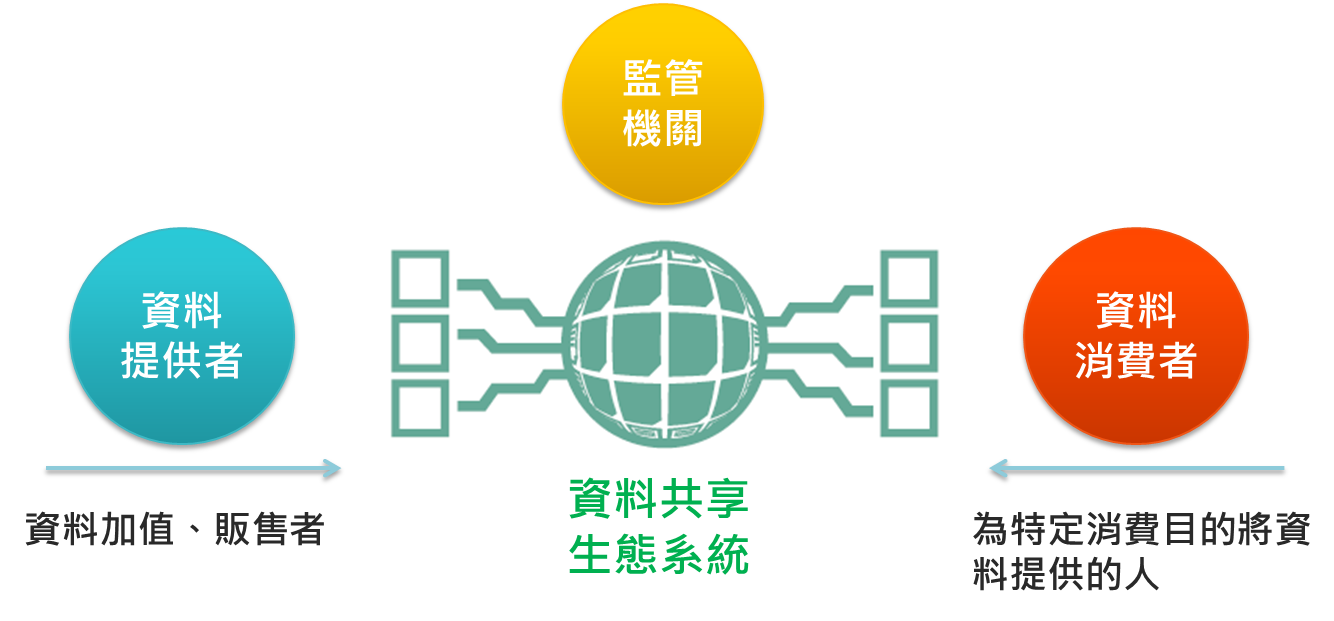
資料來源:新加坡資通發展局
一、新加坡個人資料保護法規範
在沒有個資法第17條所列之例外情形下,依據第14條以下規定,組織如近用個人資料應獲得個人同意,同時應符合目的使用及通知義務,尤其應給予個人可隨時撤回同意之權利[7]。
同時組織應根據個人要求,提供近用個人資料之方法、範圍與內容,以及更正錯誤資料權利[8]。並且組織必須任命資料保護官(Data Protection Officer, DPO)隨時向大眾提供通暢的個資聯絡管道,來確保個資透明性與完整性[9]。
在資料保護措施上應有合理安全的資安防護技術,以保障資料不被未經授權近用的風險。當使用目的不在時,需妥善保留或予以去識別化,同時如須境外轉移資料時,境外之資料保護措施應至少與新加坡個資法規範標準相同[10]。
二、免除同意之DSAs機制
DSAs機制是由個資委員會於2018年設立的沙盒(sandbox)計畫,也就是組織可透過申請免除資料共享前必須獲得個人同意之規範。然而如組織擬向個資委員會申請DSAs機制,必須符合三個條件[11]:
- 共享範圍需在特定群體、期間與組織內:即只限定在具體特定的應用情境內,若超出申請範圍,例如分享至其他非申請範圍的組織,則須再經過個資委員會批准[12]。
- 近用目的需具體明確:即資料共享必須應用於特定且明確目的,如以「社會研究目的」作為申請則範圍過大不夠明確[13]。
- 近用資料對於個人不會有不利影響,或公共利益大於個人利益:例如共享目的不是直接用於銷售或存在合法利益,或是共享本身具備公共利益且明顯大於個人可預見的(foreseeable)不利影響,此時個資委員會可考慮同意組織申請免除[14]。
三、建立以信任為基礎之資料共享模式
雖然取得DSAs機制免除同意可以使資料近用方式更為簡便,然而在進行資料共享前,仍應有完善的技術品質與資安保護措施,因此在「可信任資料共享框架」指南建議中,組織應透過法律遵循、導入AI或區塊鏈等新興技術,並具備相應資安保護措施來建構可信任的資料共享環境,實際步驟可分為以下四階段[15]:
圖2:可信任資料框架
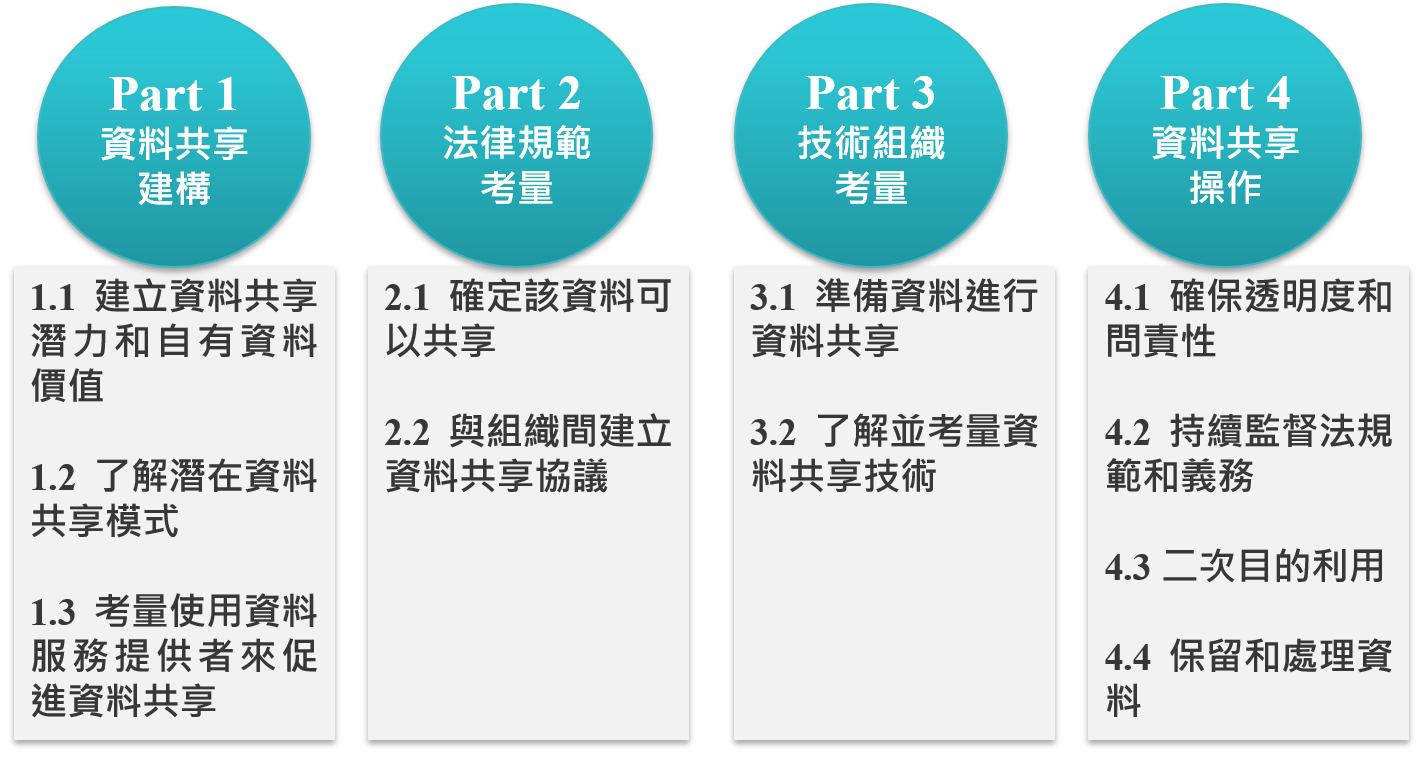
資料來源:新加坡資通發展局
第一階段為「資料共享建構」[16],由組織自行評估存有的商業或個人資料是否具共享價值與潛在利益,並要如何進行共享,例如資料共享方式屬於雙邊(bilateral)、多邊(multilateral)或是分散式(decentralized,又稱「去中心化」)。以及資料種類有哪些,如主資料(master data)、交易資料、元資料(metadata)、非結構化資料(unstructured data)等。組織可將資料共享方式、種類依據無形資產(intangible asset)評價方式,即市場法(market approach)、成本法(cost approach)與收入法(income approach)三種評價方法進行評價,來衡量共享之價值性。除資料價值判斷外,組織必須自行評估自身組織與將來之合作夥伴是否有足夠能力管控共享之資料,包括是否具備一定技術能力的資安與資料保護措施等。
第二階段為「法律規範考量」[17],即決定哪些資料可以進行共享,從規範面檢視個資法、競爭法與銀行法等是否有例外不得共享規定,例如信用卡號碼或個人生物識別資訊不得共享。若資料共享類型不會對個人造成不利影響或具備公共利益,並有通知(notification)個人給予選擇退出(opt-out)的機會,組織可依個案申請DSAs機制之豁免。同時另外鼓勵組織向IMDA申請資料保護信任標章(Data Protection Trustmark, DPTM)認證,透過認證機制使消費者更能信任組織運用其個人資料[18]。
第三階段為「技術組織考量」[19],包含組織是否有能力建立資安風險管理與個資侵害之因應措施,是否有即時將資料安全備份技術,並針對不同傳輸技術如有線/無線網路、遠端存取(VPN)、應用程式介面(API)、區塊鏈等區分不同資安防護與風險管理能力。
最後一階段為「資料共享操作」,當已準備進行資料共享時,需再次檢視是否已符合前三個階段,包含透明性、責任義務、法律遵循、近用資料方式與取得目的外利用同意等[20]。
參、事件評析
個人資料視為21世紀驅動創新的重要價值,我國部會亦開始討論「個資資產化」的可能[21]。面對數位經濟時代來臨,有效運用數位科技將潛藏個人資料的大數據進行加值利用,不僅有利組織與創新發展,更可回饋消費者享有更好的產品與服務。
新加坡政府以資料共享作為數位經濟發展重點方向之一,在具備一定程度技術能力、資安保護措施與組織控管之條件下,可向主管機關申請免除個人同意之規範。透過一定法規鬆綁讓資料利用最大化以創造產業創新價值,同時依據主管機關要求的保護措施,使消費者信賴個人資料不會遭受不當利用或侵害。DSAs機制與「可信任資料共享框架」指南之建立,適時調適個人資料保護規範與資料應用間的衝突,並提供組織進行資料共享之依循建議,作為推動該國數位經濟發展方針之一。
[1]組織(organisation)依據新加坡個人資料保護法(Personal Data Protection Act 2012)第2條泛指個人、公司、協會、法人或團體。
[2]INFOCOMM MEDIA DEVELOPMENT AUTHORITY 【IMDA】, Trusted data sharing framework (2019), at 7, https://www.imda.gov.sg/-/media/Imda/Files/Programme/AI-Data-Innovation/Trusted-Data-Sharing-Framework.pdf (last visited Sep. 11, 2019).
[3]id.
[4]Personal Data Protection Act 2012 (No. 26 of 2012) §62, “The Commission may, with the approval of the Minister, by order published in the Gazette, exempt any person or organisation or any class of persons or organisations from all or any of the provisions of this Act, subject to such terms or conditions as may be specified in the order.”
[5]Data Sharing Arrangements, PDPC, https://www.pdpc.gov.sg/Overview-of-PDPA/The-Legislation/Exemption-Requests/Data-Sharing-Arrangements (last visited Dec. 1, 2019).
[6]id.
[7]IMDA, supra note 2, at 31; Personal Data Protection Act 2012 (No. 26 of 2012) §14, 16, 20.
[8]id. Personal Data Protection Act 2012 (No. 26 of 2012) §21.
[9]IMDA, supra note 2, at 31.
[10]id. at 32. Personal Data Protection Act 2012 (No. 26 of 2012) §24-26.
[11]id.
[12]PERSONAL DATA PROTECTION COMMISSION【PDPC】, Guide to Data Sharing (2018), at 14, https://www.pdpc.gov.sg/-/media/Files/PDPC/PDF-Files/Other-Guides/Guide-to-Data-Sharing-revised-26-Feb-2018.pdf (last revised Oct. 3, 2019).
[13]id.
[14]id.
[15]PDPC, supra note 4. at 28.
[16]id. at 21, 23-25.
[17]id. at 35
[18]id. at 30. Data Protection Trustmark Certification, IMDA, https://www.imda.gov.sg/programme-listing/data-protection-trustmark-certification (last visited Sep. 26, 2019).
[19]id. at 41-47.
[20]id. at 50-51.
[21]林于蘅,〈自己的個資自己賣!國發會擬推「個資資產化」〉,聯合新聞網,2019/06/17,https://udn.com/news/story/7238/3877400 (最後瀏覽日:2019/10/1)。
- 【台北場1】通訊傳播事業個資法遵教育訓練
- 【台中場】通訊傳播事業個資法遵教育訓練
- 【新北場】通訊傳播事業個資法遵教育訓練
- 【高雄場】通訊傳播事業個資法遵教育訓練
- 【台北場2】通訊傳播事業個資法遵教育訓練
- 零售業個資法遵實務與資訊安全說明會
- 114年資訊服務業者個資安維辦法宣導說明會
- 【線上】資訊服務業個資安維計畫說明會
- 【實體】資訊服務業個資安維計畫說明會暨交流工作坊
- 零售業個資法遵實務與資訊安全說明會(台中場)
- 【台北場1】通訊傳播事業個資保護實務專題講座
- 【台北場2】通訊傳播事業個資保護實務專題講座
- 【台北場3】通訊傳播事業個資保護實務專題講座
- 金融相關資服業者線上個資安維宣導說明會
- 【上午場】探索科技法律最前線:資策會科法所「114年成果」分享會暨簡報票選
- 【下午場】探索科技法律最前線:資策會科法所「114年成果」分享會暨簡報票選
- 商業服務業個資管理與資訊安全實務宣導說明會(高雄場)
- 商業服務業個資管理與資訊安全實務宣導說明會(台南場)
- 商業服務業個資管理與資訊安全實務宣導說明會(台中場)
- 商業服務業個資管理與資訊安全實務宣導說明會(台北場)※如遇颱風假延期至7/16
- 【北部場1】國家通訊傳播委員會與通訊傳播產業個人資料保護與管理制度實務工作坊
- 【北部場2】國家通訊傳播委員會與通訊傳播產業個人資料保護與管理制度實務工作坊
- 【北部場3】國家通訊傳播委員會與通訊傳播產業個人資料保護與管理制度實務工作坊
- 【北部場4】國家通訊傳播委員會與通訊傳播產業個人資料保護與管理制度實務工作坊
- 【南部場】國家通訊傳播委員會與通訊傳播產業個人資料保護與管理制度實務工作坊
- 【中部場】國家通訊傳播委員會與通訊傳播產業個人資料保護與管理制度實務工作坊

吳昌鴻
法律研究員 編譯整理



2025年7月30日,美國加州法院指出公司濫用合作談判地位以爭奪再生能源市場之行為,從商業角度極為惡劣,將面臨重大法律風險,並認定Phillips 66能源公司須向Propel Fuels(下稱Propel)競爭公司給付共約8億美元的賠償金。 本案源於2017年,Phillips 66公司以收購為由,雙方簽署收購意向書,對Propel公司進行盡職調查。於此期間,Propel公司依保密契約向Phillips 66公司揭露其再生柴油專屬策略與資訊,Phillips 66公司並從 Propel 下載近 3千份包含營業秘密的紀錄。於2018年8月24日,Phillips 66公司突然終止收購並於下一工作日向加州監管機構宣布其將加入加州再生能源市場,2019年正式銷售高混合可再生柴油。 2022年2月16日,Propel公司向加州法院控訴Philips 66公司不當使用Propel公司花費13年研發得出之財務與銷售資料、營運模式及其再生能源業務的預測資料等營業秘密,致Propel公司損失2億美元。於2024年10月16日,本案認定Phillips 66公司違反加州統一營業秘密法(Uniform Trade Secrets Act),不當使用Propel公司的營業秘密, Phillips 66公司應賠償6.049 億美元。其後,本案認定Phillips 66公司行為屬惡意不當使用營業秘密,依加州統一營業秘密法,法院可另將懲罰性賠償金增加至2倍。2025年7月底,本案認定之賠償金達到8億美元,包含自2024年之6.049億美元的補償性賠償金,以及因Phillips 66公司「惡意」不當使用營業秘密的行為,追加1.95億美元的懲罰性賠償金。 綜觀前述實務案例可得知,即便公司間已簽訂保密契約,仍存在公司假借併購盡職調查、合作協商為由,要求他公司提供機密資料。為降低與外部合作而衍生之機密外洩風險,以下為公司提供資料對外之前、中、後階段可參考之管理建議: 1. 對外提供資料前 (1) 內規定義營業秘密搭配機密分級,了解營業秘密之範圍,並依據不同機密等級採取相應的管制措施。 (2) 對外提供資料前,營業秘密相關之權責人員應審查資料適合揭露與否。 (3) 與外部合作協商前,即應確認簽訂保密契約與約定權利歸屬。 2. 已對外提供資料 倘若已對外提供資料,建議採取限制流通、限制權限等作法,如僅限該合作計畫相關人員透過身分認證登入帳號,方有線上瀏覽機密之權限等方式。 3. 對外提供資料後 於合作結束或協商破局之情況,應要求合作方返還或銷毀營業秘密,如為銷毀,應附上相關聲明並佐證執行紀錄。 前述建議之管理作法已為資策會科法所創意智財中心於2023年發布之「營業秘密保護管理規範」所涵蓋,企業如欲精進系統化的營業秘密管理作法,可以參考此規範。 本文為資策會科法所創智中心完成之著作,非經同意或授權,不得為轉載、公開播送、公開傳輸、改作或重製等利用行為。 本文同步刊登於TIPS網站(https://www.tips.org.tw)
英國將以NHS基因體醫學服務續行十萬基因體計畫英國政府所提出的「10萬基因體計畫(100,000 Genomes Project)」將於2018年底達成目標,而將以NHS基因體醫學服務(NHS Genomic Medicine Service)作為續行計畫,以促進個人化醫療的發展。 NHS基因體醫療服務的目的在於促進罕見疾病與癌症的診斷以及患者治療的效率,並預期在未來5年達到五百萬組基因定序,以提供具備全面性(comprehensive)以及公正性(equitable)的基因檢測。為達此目的,NHS基因體醫療服務包含5個主要內涵:連結基因體研究中心以成立國家基因體實驗室服務(national genomic laboratory service)、新的國家基因體實驗室檢測文庫(new National Genomic Test Directory)、全基因體定序的相關規範,並與英國基因體公司(Genomic England)合作開發資訊基礎設施(informatics infrastructure)、臨床基因體醫學服務(clinical genomics medicine services)以及發展基因體醫學中心服務(Genomic Medicine Centre service)、NHS負擔統合性的監管職責。 在以NHS基因體醫療服務作為續行計畫的狀況下,若合格的研發人員欲以患者的基因資料進行新藥或是新治療方式的開發需事先取得患者的同意。另外,從2019年開始,全基因定序將被納入特定患者的治療過程中,如罹患特定罕見疾病或具有治癒困難性的成年患者以及所有患有嚴重疾病的孩童患者,以加速疾病的診斷以及減少侵入性治療的次數。
何謂「Society 5.0」日本科技政策的制定依據來自日本「科學技術基本法」,該法第九條規定,要求國家在推動科技振興發展上,政府應制訂有關科學技術振興的「科學技術基本計畫」。「科學技術基本計畫」之推動以五年為一期,最近一期為第五期(2016-2020年),該期計畫以人工智慧與資通訊技術為核心,解決各式重要社會課題,打造「超智慧社會」,並命名為「Society 5.0」。 「Society 5.0」明訂日本實現超智慧社會的政策方向,其政策重點聚焦於產業創造與社會變革,並重新架構產業與整個社會的關係,因此,除了強化產業競爭力,實現產業變革以外,「Society 5.0」也規劃解決日本近年社會課題,包括老齡化社會、勞動力不足、能源短缺與自然災害等。而在前瞻性預測上,「Society 5.0」描繪20年後未來人類將生活在為高度電腦化、智慧化環境,為實現該目標,發展物聯網、大數據分析、電腦科學與技術、人工智慧與網路安全等相關科技基礎技術研發與應用,是「Society 5.0」的核心之一。 簡單來說,「Society 5.0」追求以人為中心的新經濟社會,運用高度融合網路虛擬空間及物理現實空間的相關技術,滿足未來人類生活上的各種需求,同步解決經濟發展與社會課題,並以此建構更貼近符合個人需求之社會。
德國巴伐利亞邦政府聲明其執行DSGVO(GDPR)的方式─對中小企業及協會友善的輔導今年7月31日最新一期的巴伐利亞邦政府公報(Allgemeines Ministerialblatt, AllMBl),揭露今年6月5日的巴伐利亞內閣會議紀錄─關於巴伐利亞邦執行DSGVO的方式。 公報內容指出幾個重點: 業餘體育俱樂部(Amateursportverein)、樂隊(Musikkapelle)或由志願者投入者組成的協會(Verein),不須任命資料保護官員(Datenschutzbeauftragten, DSB)。 如果因為對法律的不熟悉而初次違反DSGVO,並不會被罰款;相關單位的指示和建議將優先於處罰。因依據DSGVO第83條第1項規定,處罰應該是有效、適當且具有懲戒性的。故對於非第一次違反的情況,就可能直接依據DSGVO第83條規定處以罰款。 巴伐利亞邦不能接受「警告律師」(Abmahnanwälten)告誡企業資料保護行為違規的做法。 邦政府將向有關單位進一步確認DSGVO中的相關規定,其應用尤其必須能夠確保正確且適當的符合DSGVO的目標。 邦政府將與協會和中小企業進行進一步有關DSGVO適用的討論。 在巴伐利亞邦政府公布的新聞稿中,總理馬庫斯索德進一步表示:「DSGVO實現了更大程度的隱私保護,但不應該成為官僚主義的怪物。巴伐利亞將提供對協會及中小企業都友善的DSGVO適用方式。我們提供的是幫助,而不是懲罰。」內政部長Joachim Herrmann則表示:「DSGVO希望促使人民接受,但不是在人民的日常生活製造更多的困擾和額外的官僚主義。最重要的是,所有的協會、許多有志願者投入的地方或中小企業,必須透過適當和正確地應用DSGVO,來保護其免受過度的資料保護要求。」 巴伐利亞資料保護監督辦公室(BayLDA, Bayerische Landesamt für Datenschutzaufsicht)並進一步公布了對許多中小企業,如:協會、醫療診所(Arztpraxis)、稅務顧問(Steuerberater)……等行業,遵循DSGVO的參考指引,提供進一步的遵循指示。