世界經濟論壇發布《人工智慧公平性和包容性藍圖》白皮書

世界經濟論壇(World Economic Forum, WEF)於2022年6月29日發布《人工智慧公平性和包容性藍圖》白皮書(A Blueprint for Equity and Inclusion in Artificial Intelligence),說明在AI開發生命週期和治理生態系統中,應該如何改善公平性和強化包容性。根據全球未來人類AI理事會(Global Future Council on Artificial Intelligence for Humanity)指出,目前AI生命週期應分為兩個部分,一是管理AI使用,二是設計、開發、部署AI以滿足利益相關者需求。
包容性AI不僅是考量技術發展中之公平性與包容性,而是需整體考量並建立包容的AI生態系統,包括(1)包容性AI基礎設施(例如運算能力、資料儲存、網路),鼓勵更多技術或非技術的人員有能力參與到AI相關工作中;(2)建立AI素養、教育及意識,例如從小開始開啟AI相關課程,讓孩子從小即可以從父母的工作、家庭、學校,甚至玩具中學習AI系統對資料和隱私的影響並進行思考,盡可能讓使其互動的人都了解AI之基礎知識,並能夠認識其可能帶來的風險與機會;(3)公平的工作環境,未來各行各業需要越來越多多元化人才,企業需拓寬與AI相關之職位,例如讓非傳統背景人員接受交叉培訓、公私協力建立夥伴關係、提高員工職場歸屬感。
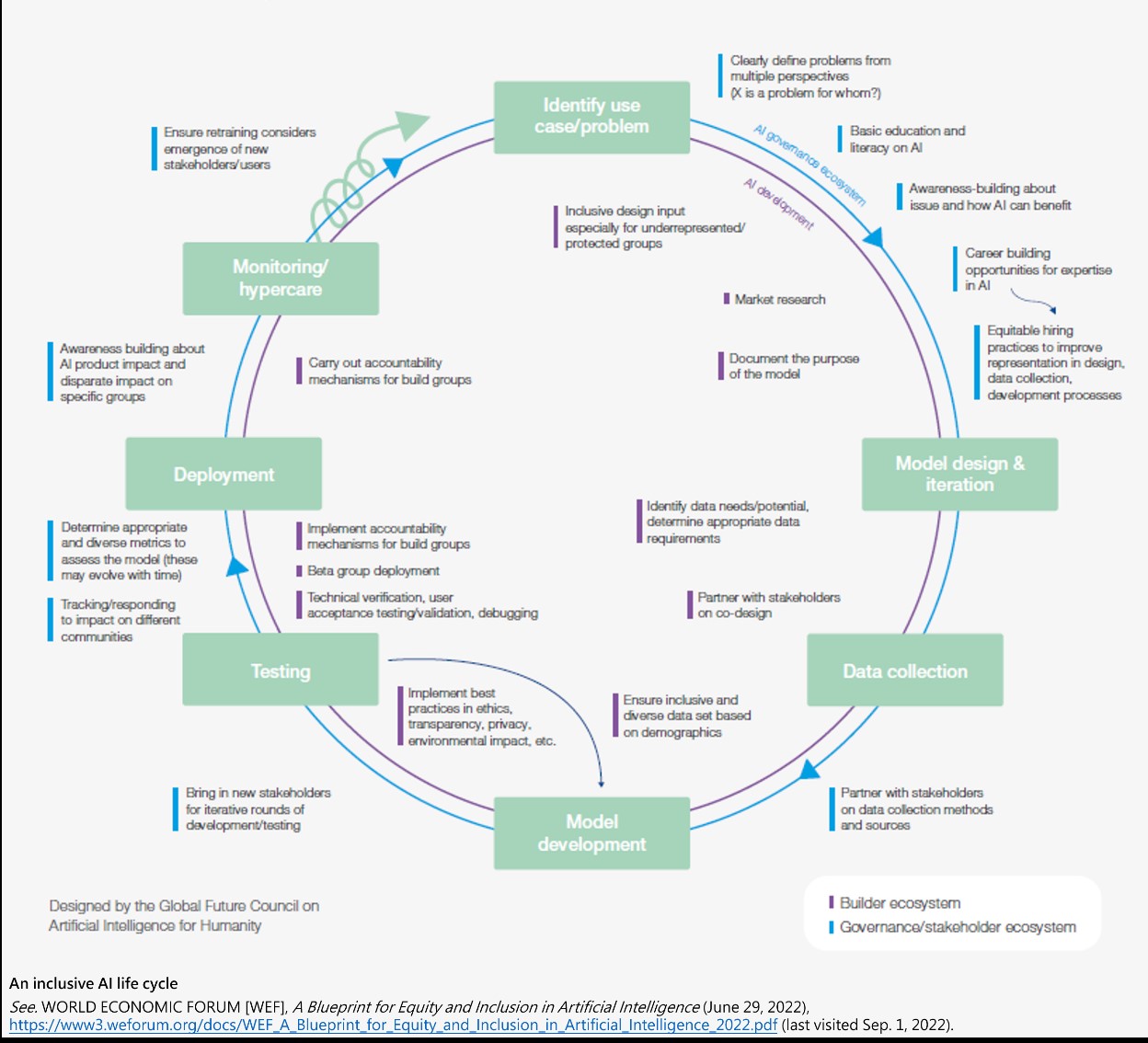
在設計包容性方面,必須考慮不同利益相關者之需求,並從設計者、開發者、監督機關等不同角度觀察。本報告將包容性AI開發及治理整個生命週期分為6個不同階段,期望在生命週期中的每個階段皆考量公平性與包容性:
1.了解問題並確定AI解決方案:釐清為何需要部署AI,並設定希望改善的目標變量(target variable),並透過制定包容性社會參與框架或行為準則,盡可能實現包容性社會參與(特別是代表性不足或受保護的族群)。
2.包容性模型設計:設計時需考慮社會和受影響的利益相關者,並多方考量各種設計決策及運用在不同情況時之公平性、健全性、全面性、可解釋性、準確性及透明度等。
3.包容性資料蒐集:透過設計健全的治理及隱私,確定更具包容性的資料蒐集路徑,以確保所建立之模型能適用到整體社會。
4.公平和包容的模型開發及測試:除多元化開發團隊及資料代表性,組織也應引進不同利益相關者進行迭代開發與測試,並招募測試組進行測試與部署,以確保測試人群能夠代表整體人類。且模型可能隨著時間發展而有變化,需以多元化指標評估與調整。
5.公平地部署受信任的AI系統,並監控社會影響:部署AI系統後仍應持續監控,並持續評估可能出現新的利益相關者或使用者,以降低因環境變化而可能產生的危害。
6.不斷循環發展的生命週期:不應以傳統重複循環過程看待AI生命週期,而是以流動、展開及演變的態度,隨時評估及調整,以因應新的挑戰及需求,透過定期紀錄及審查,隨時重塑包容性AI生態系統。
綜上,本報告以包容性AI生態系統及生命週期概念,期望透過基礎設施、教育與培訓、公平的工作環境等,以因應未來無所不在的AI社會與生活,建立公司、政府、教育機構可以遵循的方向。
- World Economic Forum [WEF], A Blueprint for Equity and Inclusion in Artificial Intelligence (June 29, 2022)
- A Blueprint for Equity and Inclusion in Artificial Intelligence, World Economic Forum (June 29, 2022)
- Global Future Council on Artificial Intelligence for Humanity, World Economic Forum (June 29, 2022)

許嘉芳
法律研究員 編譯整理
World Economic Forum [WEF], A Blueprint for Equity and Inclusion in Artificial Intelligence (June 29, 2022), https://www3.weforum.org/docs/WEF_A_Blueprint_for_Equity_and_Inclusion_in_Artificial_Intelligence_2022.pdf (last visited Sep. 1, 2022).
A Blueprint for Equity and Inclusion in Artificial Intelligence, World Economic Forum (June 29, 2022), https://www.weforum.org/whitepapers/a-blueprint-for-equity-and-inclusion-in-artificial-intelligence (last visited Sep. 1, 2022).
Global Future Council on Artificial Intelligence for Humanity, World Economic Forum (June 29, 2022), https://www.weforum.org/communities/gfc-on-artificial-intelligence-for-humanity (last visited Sep. 1, 2022).
王柏霳,〈美國國家標準暨技術研究院規劃建立「人工智慧風險管理框架」,並徵詢公眾對於該框架之意見〉,2021年10月, https://stli.iii.org.tw/article-detail.aspx?tp=1&d=8727&no=64(最後瀏覽日:2022/09/02)。

 科法觀點
科法觀點

美國能源部今(2012)年5月宣布1千1百萬美元的預算,獎勵小型企業發展潔淨能源創新研究與科技。美國的小型企業並非以營運的領域來區分,而且必須合於美國聯邦法規(13 CFR 121)中對於小型企業的規範,另外,美國小型企業管理局(U.S. Small Business Administration,SBA)對於各種營利活動亦建立有大小區分的標準,依照不同的行業別,就員工人數或營業額的數目訂立區分標準。因為企業大小的區分,在美國政府採購契約發包的程序上極為重要,因為他們確保,為大小不等的小企業之間提供公平的競爭基準,而這些區分標準同時也適用在SBA的貸款/補助計畫以及能源部小型企業創新研究計畫(Small Business Innovation Research ,SBIR)與小型企業技術移轉計畫(Small Business Technology Transfer ,STTR)上。 能源部此次小型企業創新研究計畫是歐巴馬政府為扶持小型企業,增加美國就業機會政策的一部分,計畫內容在於,給予每個小型企業最高15萬美元的補助金,只要企業的業務致力於發展創新能源技術,製造新的工作機會,以提高美國在世界的經濟競爭力,這些獲選企業在未來兩年內,可以參加第二階段的競賽,並將有機會獲得高達2百萬美元的獎勵金,目前已有67個小型企業,總共75項創新研究計畫,包括風力渦輪機、燃料電池技術以及煤炭能源等的相關研究工作,這些獲選的小型企業遍佈全美各州。 美國政府認為,小型企業為其經濟體的主幹,提供全美二分之一的工作機會,並且在國內持續製造三分之二的新就業機會,重要的是,這些企業正在幫助美國減輕對進口石油的依賴,保護美國的環境,降低環境污染。而為了支持這些小型企業在國內經濟體所扮演的重要角色, 在能源部主責進行的SBIR計劃和STTR計劃中,持續支持科學卓越和技術創新,以達強化國家經濟的目標。
eBay網站因販賣仿冒品被法國法院判決敗訴並須賠償原品牌業者繼eBay 於 今年6月4日因未制止網拍業者於eBay 網站上拍賣仿冒品被法國法院( The Tribunal de Grande Instance in Troyes)判決敗訴 、 須與網拍業者共同賠償精品業者愛瑪士 (Hermes)2萬歐元後,不到一個月的時間,另一法國法院( The Tribunal de Commerce in Paris) 於6月30日再度判定eBay因任由網拍業者拍賣仿冒物品而需賠償LVMH集團共3860萬歐元並禁止eBay在其網站上販賣LVMH集團旗下包括迪奧(Dior)、嬌蘭(Guerlain)、紀梵希(Givenchy)及Kenzo 4個品牌之香水。 eBay 表示為了保護品牌業者的智慧財產權,其已投資了超過2000萬美元建置相關機制(The Verified Rights Owner) 讓品牌業者可以容易的發現仿冒的網拍品並通知eBay 將該物品下架。但愛瑪士及LVMH集團皆認為該機制尚不足以杜絕仿冒品的銷售。 針對LVMH之判決,Vanessa Canzini, eBay 的發言人表示 “如果有仿冒品出現在eBay 的網站上, eBay會迅速地將該物品下架,但此次的判決非關仿冒品”。 Sravanthi Agrawal, eBay 的另一發言人表示 “此次判決的重點在銷售管制 (指LVMH集團企圖壟斷其銷售管道),因eBay 並非LVMH集團所授權的銷售管道之一”。 eBay 表示LVMH集團的壟斷行為將對消費者造成傷害,將代表消費者提起上訴。 以上兩案經由法國法院針對拍賣網站提供平台販售仿冒品之判決結果預計將於國際間引發連鎖效應。一位美國智財律師表示美國法院目前認為在美國商標法下,eBay 有義務將仿冒品從其網站上移除。而法國法院的判決則更進一步要求拍賣網站在仿冒品被放上網站拍賣前就有義務制止其被拿出來販售。法國法院的見解如未被推翻將可能鼓勵其它國法院針對類似案件做出相同的判決結果。
因應韓美自由貿易協定,韓國實施新修正之專利及商標制度韓國特許廳於2011年11月22日送交韓國國會批准之韓美自由貿易協定(Free Trade Agreement,簡稱FTA),於2012年3月15日正式生效。為因應韓美FTA的簽定,韓國專利及商標制度均須進行一定幅度的修正,例如專利權存續期間延長、聲音及氣味得註冊為商標等新制度。 首先,專利法修正重點如下: 專利權存續期間延長:指針對因審查過程緩慢,導致專利登記遲延者,遲延期間得視為專利權之存續期間。 專利申請優惠期延長:專利申請人將其發明公開發表在學術期刊時,將申請之優惠期從公開後6個月延長至12個月,亦即12個月內提出申請仍可取得專利。 廢止專利權撤銷制度:將發明專利在韓國國內一定期間(最少5年)不實施之撤銷專利權事由,予以廢止。 其次,商標法修正重點如下: 增訂新型態商標及證明標章制度:聲音、氣味得註冊為商標;新增證明標章之保護態樣,以證明「品質」、「原產地」、「生產方法」等特性。 廢止商標之專用使用權登記制度:修法前之韓國商標法第56條第1項第2款規定,商標專用使用權之設定、移轉(一般繼承之情形除外)、變更、消滅(權利混同之情形除外)或處分之限制等事項,非經登記,不生效力。 新增法定損害賠償制度:商標權人除可依照實際侵害情況請求損害賠償,商標法亦新增權利人得請求法定5千萬韓圜範圍內的損害賠償金額,且須經法院判決同意該損害賠償額度。 此外,針對專利法、新型專利法、設計保護法、商標法、不正競爭防止及營業秘密保護法等法規,也一併新增「保密命令制度」,亦即透過訴訟程序,對於營業秘密有被公開之虞之情形時,法院可對雙方當事人作出不得公開之保密命令。韓國期透過此次專利法及商標法等相關法規之修正,讓專利權人於權利行使期間得以獲得實質保障,同時亦擴大企業商標選擇之範圍。
美國航空公司控告Google銷售不當的關鍵字廣告美國航空公司(American Airlines, 以下簡稱AA),世界最大的航空公司,控告Google私自銷售包含AA的名稱或註冊商標之搜尋關鍵字 AA日前向德州北區地方法院提出訴訟,控告Google將關於AA的名稱或註冊商標的搜尋關鍵字,如「American Airlines」或「AA.com」,銷售給其它公司作為廣告用途。 AA表示,Google甚至將該等搜尋關鍵字銷售給AA的競爭者。換言之,當使用者於Google搜尋引擎查詢關於前述之AA名稱或註冊商標之關鍵字時,Google除了提供相關連結之外,也可能會在「贊助者連結」中提供AA競爭者的連結,而引導使用者前往其競爭者的網頁。 AA於聲明中指出:「我們希望能減輕此類行為所造成的損害」。截至目前為止,AA並未透露求償金額等細節。 Google則在其聲明中指出:「我們相信本公司的商標政策已經在商標所有人的權益以及消費者的選擇之間取得適當的平衡,並且我們的立場在相關案例的判決中已經被證實是合法的」。